Paperless-ngx: (Libre-) Office Dateien verwalten
- 7 minutes read - 1280 wordsIn den letzten Artikel über Paperless-ngx bin ich nur auf die Verwaltung von PDF-Dateien eingegangen. Nun kommt es aber unregelmäßig bei mir auch immer mal wieder vor, dass ich Office-Dokumente mit LibreOffice erstelle, also z. B. eine Kündigung schreibe, die ich dann entweder als PDF oder aber als Papierbrief versende.
Das PDF kann man natürlich direkt in Paperless-ngx zur Archivierung ablegen. Aber was ist mit dem Office-Dokument? Das Original einfach auf dem Notebook lassen? Dann bräuchte man hier aber auch wieder eine Ablagestruktur. Oder das Original einfach vergessen? Auch doof. Kündigungsschreiben und Co. lassen sich ja ziemlich gut recyceln. Also ist es nicht schlecht, wenn man dies immer als Template verfügbar hat.
Für dieses Problem gibt es in Paperless-ngx seit einiger Zeit auch eine Lösung. Neben einfachen Text-Dokumenten, PDFs und JPEGs, die schon immer verarbeitet werden können, können dank der Integration von Tika und Gotenborg nun auch Office-Dokumente abgelegt werden.x
Workflow
Die Office-Dokumente können damit, genauso wie PDFs, einfach in Paperless-ngx per Webinterface oder Consume-Ordner hochgeladen werden und Paperless-ngx erstellt eine PDF-Version des Dokuments. Das Verhalten ist also erst mal nicht anders, als wenn man direkt ein PDF hochläd. Der Unterschied: Über den Button Download Original, erhält man das Office Dokument zurück und kann dieses wieder weiter verarbeiten.
Paperless-ngx ist hier sicher kein Ersatz für eine mächtige Lösung wie Sharepoint. Aber es geht hier ja auch um das private Büro. Für die wenigen Briefe und Dokumente ist dieser Worflow allemal ausreichend. Und der große Vorteil: Wirklich alle Dokumente befinden sich in Paperless-ngx. Ein Notebook-Wechsel oder -Crash ist also kein ernsthaftes Problem mehr. Auf dem Notebook befinden sich immer nur temporäre Dateien.
Paperless-ngx ist also die “Single Source of Truth”.
Setup Tika & Gotenborg
Setup Dokumentation: Link zur Doku
Link zur Beispielkonfiguration in Github: Link zu Github
Das Setup ist schnell erledigt. Letztendlich müssen nur ein paar wenige Handgriffe in der docker-compose.yml erledigt werden. Hierfür kann man sich am auf Github bereitgestellten Beispiel orientieren. Hat man die Abschnitte hinzugefügt, dann nur nur noch ein docker-compose up -d und schon läuft wieder alles.
Dokumente hochladen
In der Oberfläche und bei der Benutzung von Paperless-ngx hat sich erst mal nichts verändert. Einziger Unterschied: Es können nun eben auch (Libre-) Office Dokumente hochgeladen werden.
Nach dem erfolgreichen Upload erzeugt Paperless-ngx daraus ein PDF/A für die Archivzwecke und legt zudem das Original Office Dokument ab.
Dokumente herunterladen
Entsprechend können auch beide Varianten herunterladen werden. Klickt man auf den “Download”-Button, wir einem das PDF/A zum Herunterladen angeboten. Klickt man auf den “Download original”-Button im Kontextmenü, erhält man das Office-Dokument zurück.
Automatische Klassifizierung
Der Workflow hat nun noch einen Nachteil. Man kann auf den ersten Blick in Paperless-ngx nicht erkennen, ob man nun ursprünglich ein PDF-Dokument oder ein Office-Dokument hochgeladen hat.
Zur Erinnerung, mein persönlicher Workflow sieht so aus:
- Ich erstelle ein Dokument mit LibreOffice.
- Versende ich dieses als Brief (Papier und Briefmarke und so), dann scanne ich dieses Dokument vor dem Absenden für die Archivzwecke ein.
- Versende ich das Dokument als PDF, dann erzeuge ich aus Libreoffice heraus das PDF und hebe auch dieses PDF auf.
- Nun archiviere ich sowohl das PDF als auch das LibreOffice Dokument.
Der Nachteil: Lade ich PDF und LibreOffice Dokument gleichzeitig in Paperless-ngx hoch, kann ich zwischen den beiden erst mal nicht mehr unterscheiden. Hierfür müsste ich erst per “Download original”-Button prüfen, ob es sich nun um das archivierte PDF oder das LibreOffice Dokument handelt und manuell einen Tag vergeben.
Leider unterstützt Paperless-ngx das Klassifizieren anhand des Dateinamens nicht. Sonst könnte man einfach eine entsprechende Regel für einen Tag oder Document Type festlegen bzw. auf das neuronale Netzwerk setzen. Aber Dateinamen und Dateitypen werden nicht ausgewertet.
Es muss also ein wenig tiefer in die Trickkiste gegriffen werden. Wir benötigen zwei Tools von Paperless-ngx:
- Die REST Api: Hiermit können Dokumente in der Datenbank von Paperless-ngx bearbeiten. Also z.B. Tags hinzufügen oder den Document Type ändern. Natürlich können wir auch Informationen auslesen. Dokumentation zur REST API
- Post-consumption scripte: Wir haben bei Paperless-ng die Möglichkeit, entweder bevor der Consumer gelaufen ist, in den Prozess einzugreifen oder hinterher. Dokumentation zu Post-consumption scripten
Bringen wir diese beiden Dinge zusammen, ist das Problem gelöst. Direkt nachdem der Consumer von Paperless-ngx gelaufen ist, also eine Datei zur Datenbank hinzugefügt hat, klassifizieren wir diese als Document Type “Office Document” anhand der Dateiendung.
Das passende Script sieht so aus:
#!/usr/bin/env bash
DOCUMENT_ID=${1}
DOCUMENT_FILE_NAME=${2}
DOCUMENT_SOURCE_PATH=${3}
DOCUMENT_THUMBNAIL_PATH=${4}
DOCUMENT_DOWNLOAD_URL=${5}
DOCUMENT_THUMBNAIL_URL=${6}
DOCUMENT_CORRESPONDENT=${7}
DOCUMENT_TAGS=${8}
if [[ "$DOCUMENT_FILE_NAME" == *.ods ]];
then
curl -H "Authorization: Token 4a98c9f72f0e9337fdc2f56e0d574685cfef93e7" -X PATCH -d 'document_type=33' http://localhost:8000/api/documents/${DOCUMENT_ID}/
fi
if [[ "$DOCUMENT_FILE_NAME" == *.odt ]];
then
curl -H "Authorization: Token 4a98c9f72f0e9337fdc2f56e0d574685cfef93e7" -X PATCH -d 'document_type=33' http://localhost:8000/api/documents/${DOCUMENT_ID}/
fi
Dieses Script muss nun noch so abgelegt werden, dass es innerhalb des Docker Containers verfügbar ist und auch nach einem Update des Containers nicht verloren geht.
Es bietet sich also an, das data-Verzeichnis zu verwenden, welches im docker-compose.yml so definiert ist:
- data:/usr/src/paperless/data
Um nun den lokalen Pfad zu ermitteln, hilft ein docker volume inspect paperlessng_data:
docker volume inspect paperlessng_data
[
{
"CreatedAt": "2021-06-24T10:32:55+02:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/paperlessng_data/_data",
"Name": "paperlessng_data",
"Options": null,
"Scope": "local"
}
]
Also legen wir das Script einfach dort ab und sorgen dafür, dass es ausführbar ist. In meinem Fall wäre dies /var/lib/docker/volumes/paperlessng_data/_data.
Nun muss Paperless-ngx noch klar gemacht werden, dass es ein post-consumption script ausführen soll. Dies funktioniert wieder in der docker-compose.yml:
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
[...]
environment:
[...]
PAPERLESS_POST_CONSUME_SCRIPT: /usr/src/paperless/data/post_consume.sh
Im Anschluss kann Paperless-ngx mit docker-compose neu gestartet werden und nun wird automatisch bei jedem neu hochgeladenen ods- oder odt-Dokument der “Document Type” auf “Office Dokument” geändert. Es ist ab sofort also nun auf den ersten Blick in der GUI möglich, zwischen PDF und Office-Dokument zu unterscheiden.
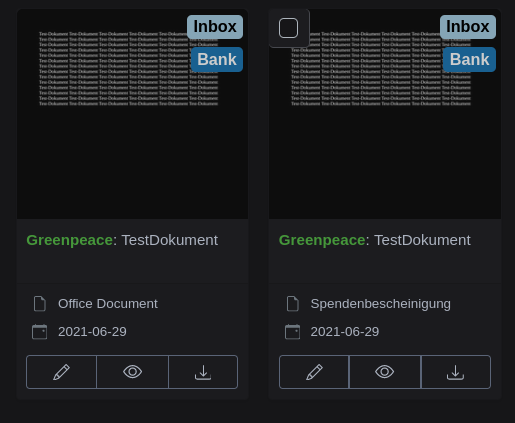
Wieder ein Schritt der die Dokumentenverwaltung im papierlosen privaten Büro deutlich vereinfacht.
Update 02/2022
Abschnitt nicht mehr relevant
Vielen Dank an svenpaush für diesen Hinweis: Aktuell stagniert die Entwicklung von Paperless-ng. Die Entwicklung von gotenberg und tika ging die letzten Monate jedoch weiter. Die API von Gotenberg hat sich mit den letzten Versionen geändert, so dass diese nicht mehr mit Paperless-ng zusammenpassen. Damit das Zusammenspiel wieder funktioniert, muss man im docker-compose.yml die Versionen von Gotenberg und Tika festlegen:
gotenberg:
image: thecodingmachine/gotenberg:6
...
tika:
image: apache/tika:1.27
Ich habe das docker-compose.yml im Artikel entsprechend ergänzt.
Update 07/2022
Nachdem die Entwicklung mit Paperless-ngx nun wieder Fahrt aufgenommen hat, hat sich auch das Docker-Compose File und die Versionen der Container geändert. Am besten ist es sich an das offizielle Docker-Compose auf Github zu halten: Link zum Docker Compose auf Github
Die unter dem Update 02/2022 genannten Anpassungen sind nicht mehr notwendig.
Die im folgenden genannten Anpassungen bzgl. Port 3000, sind bei mir nicht mehr notwendig, da ich aktuell kein Grafana mehr verwende. Der Vollständigkeit halber, lasse ich das alte Beispiel hier jedoch stehen, kann aber nicht sagen, ob die Konfiguration mit Paperless-ngx so noch funktionieren würde:
Auf meinem Rechner ist jedoch bereits Port 3000 von Grafana belegt. Der Port von Gotenborg musste also von mir auf 3001 angepasst werden. Die zugehörigen Auszüge aus meinem docker-compose.yml sehen also so aus:
...
webserver:
image: jonaswinkler/paperless-ng:latest
restart: always
depends_on:
- db
- broker
- gotenberg
- tika
ports:
- 8000:8000
volumes:
- data:/usr/src/paperless/data
- media:/usr/src/paperless/media
- ./export:/usr/src/paperless/export
- /home/rs/consume:/usr/src/paperless/consume
env_file: docker-compose.env
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_TIKA_ENABLED: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://gotenberg:3001
PAPERLESS_TIKA_ENDPOINT: http://tika:9998
gotenberg:
image: thecodingmachine/gotenberg:6
restart: unless-stopped
environment:
DISABLE_GOOGLE_CHROME: 1
DEFAULT_LISTEN_PORT: 3001
tika:
image: apache/tika:1.27
restart: unless-stopped
Um das Port-Problem zu lösen, ist der modifizierten Eintrag PAPERLESS_TIKA_GOTENBERG_ENDPOINT bei webserver und der zusätzliche Parameter DEFAULT_LISTEN_PORT bei gotenborg notwendig. Der Rest entspricht dem Template von Github.
Dank & Feedback
Titel-Photo by Maarten van den Heuvel on Unsplash
Ich freue mich über Feedback. Schreibt mir gerne per Mastodon.